Olá,
O ElasticSearch é um mecanismo de busca e análise distribuído de código aberto, que permite realizar pesquisas em tempo real em grandes conjuntos de dados. Ele é construído sobre o Apache Lucene e permite que os usuários realizem pesquisas de texto completo, análise de dados e métricas. Ele é construído sobre o Apache Lucene, um mecanismo de pesquisa de código aberto e é projetado para ser altamente escalável e distribuído, permitindo que os usuários executem pesquisas em grandes conjuntos de dados em tempo real.
O ElasticSearch é composto por um cluster de nós, com cada nó armazenando e indexando dados. Ele usa o conceito de shards, que são partições dos dados, que são distribuídas pelos nós no cluster.
Uma shard é basicamente um fragmento de um índice que contém uma parte dos dados indexados e os documentos associados a esses dados. Cada shard é um índice separado, com seu próprio conjunto de documentos e metadados. Os shards são distribuídos entre os nós do cluster, permitindo que a pesquisa seja distribuída e escalável.
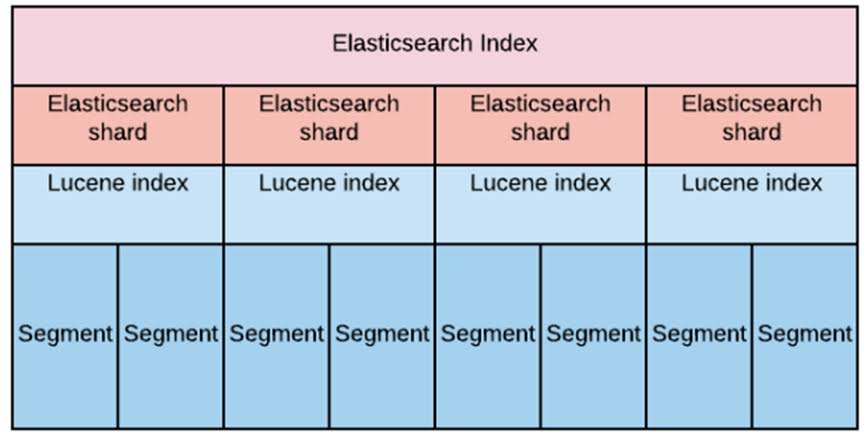
Existem dois tipos de shards no Elasticsearch: shards primárias e réplicas de shards. Uma shard primária é a shard que contém a fonte de dados e os documentos associados. Cada documento é armazenado em uma shard primária. As réplicas de shard são cópias de uma shard primária e são usadas para garantir a disponibilidade e a recuperação de desastres. A configuração do número de shards e réplicas em um índice é importante para o desempenho e escalabilidade do cluster. É importante equilibrar o número de shards e réplicas com a capacidade de hardware do cluster. Configurar um número excessivo de shards pode afetar o desempenho do cluster, pois cada shard consome recursos de hardware e pode aumentar o tempo de recuperação de desastres.

Um cluster de Elasticsearch consiste em vários nós que trabalham juntos para armazenar e pesquisar dados. Como exemplo, dois tipos de nós no Elasticsearch são o master node e o data node. De modo bem simples, na imagem abaixo irei chamar os data nodes de Slave Nodes.
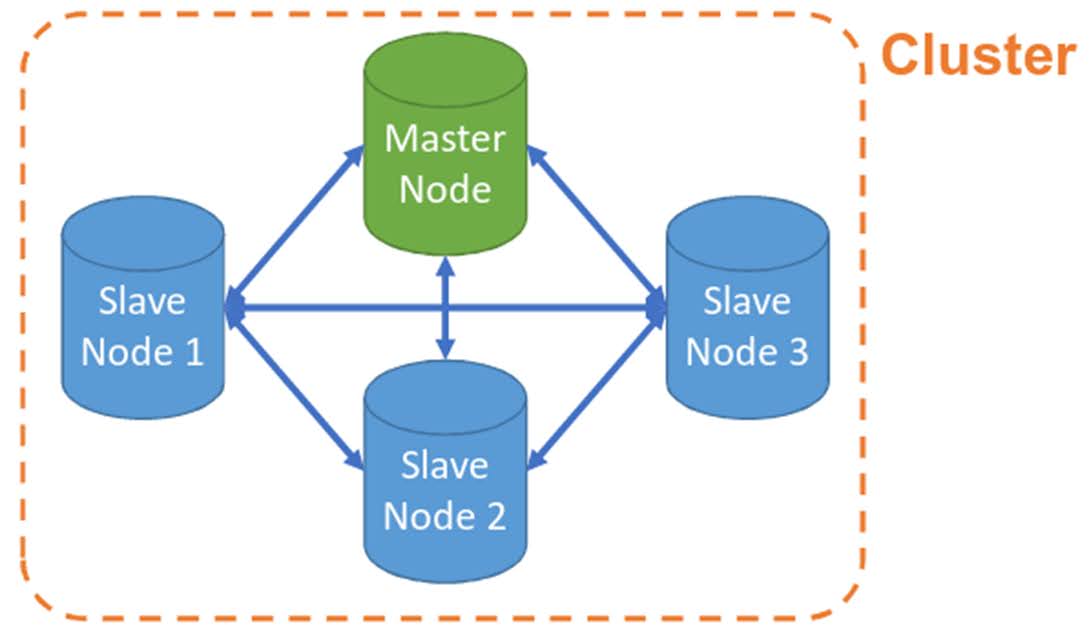
O master node é responsável por gerenciar o cluster e coordenar as atividades de todos os outros nós do cluster. Ele é responsável por atribuir shards primárias a nós de dados disponíveis, monitorar a saúde do cluster e gerenciar a configuração do cluster. O master node é crucial para garantir a disponibilidade e a integridade dos dados no cluster.
Os data nodes são os nós que armazenam e manipulam os dados. Eles são responsáveis por indexar, armazenar e recuperar os dados. Eles também gerenciam as réplicas de shards que são distribuídas em todo o cluster. Os data nodes são otimizados para armazenamento e processamento de dados e são responsáveis por executar operações de pesquisa e análise em grande escala.
É importante entender a diferença entre os nós de dados e os nós de master no Elasticsearch. Os nós de dados são responsáveis pelo armazenamento e processamento dos dados, enquanto os nós de master gerenciam o cluster e atribuem as shards primárias a nós de dados disponíveis. A separação dessas funções ajuda a garantir que o cluster possa lidar com grandes volumes de dados e mantém a integridade dos dados.
Em um cluster típico de Elasticsearch, é comum ter vários nós de dados e no mínimo três nós de master. Há casos também em clusters pequenos onde os nós são master e data ao mesmo tempo. Ter vários nós de dados permite que o cluster lide com grandes volumes de dados e forneça alta disponibilidade de dados. Ter três nós de master fornece redundância e ajuda a evitar pontos únicos de falha no gerenciamento do cluster.

Para garantir o bom desempenho e escalabilidade de um cluster Elasticsearch, existem algumas práticas recomendadas que podem ser seguidas:
- Distribua os nós do cluster: É importante ter vários nós distribuídos em diferentes servidores físicos ou virtuais, de preferência em diferentes zonas de disponibilidade, para garantir a alta disponibilidade e resiliência do cluster.
- Configure as réplicas adequadamente: Configure as réplicas do cluster para garantir que os dados sejam distribuídos em diferentes nós para garantir a resiliência e a alta disponibilidade do cluster. O número de réplicas deve ser baseado na quantidade de dados, a carga do cluster e o requisito de tempo de recuperação.
- Monitoramento regular: Monitore o cluster regularmente para garantir o bom desempenho, identificar gargalos e otimizar a configuração. Monitoramento regular pode ajudar a identificar problemas antes que eles afetem a disponibilidade do cluster.
- Otimização de configuração: Configure o Elasticsearch adequadamente com base na carga de trabalho e nos recursos do hardware disponíveis. É importante otimizar as configurações de JVM, número de shards e réplicas, cache e segmentos para garantir o desempenho ideal do cluster.
- Gerenciamento de índices: Divida os dados em índices separados para gerenciamento eficiente e use a rotação de índices para melhorar o desempenho do Elasticsearch. Além disso, elimine índices desnecessários para liberar recursos do cluster.
- Backup regular: É importante fazer backup regular dos dados do Elasticsearch para garantir a recuperação de dados em caso de falha do cluster. Faça backup dos dados em locais diferentes para garantir a segurança dos dados. O backup é realizado através de snapshots.
- Segurança: Configure a segurança do Elasticsearch para garantir que os dados do cluster estejam seguros e não acessíveis a pessoas não autorizadas.
Seguindo essas práticas recomendadas, você pode garantir que seu cluster Elasticsearch tenha desempenho ideal, seja escalável e tenha alta disponibilidade. Além disso, é importante manter-se atualizado sobre as atualizações e recursos do Elasticsearch e implementar essas práticas recomendadas de forma consistente para garantir o sucesso do seu cluster.











Nenhum comentário:
Postar um comentário