Olá,
Fazendo algumas leituras aqui e ali em forums, blogs, entre outros sites, percebo que muitos profissionais, sejam eles iniciantes ou veteranos na tecnologia do banco de dados Oracle, ainda não entendem corretamente a dinâmica de funcionamento de alguns conceitos que envolvem alguns processos de segundo plano do Oracle como o Log Writer (LGWR), o Database Writer (DBWn), o Checkpoint (CKPT), além de confundir ou interpretar de forma equivocada o significado e a consequência em alterar uma tabela para o modo NOLOGGING. De vez em quando recebo algumas questões referentes aos conceitos ACID - (A)tomicidade, (C)onsistência, (I)solamento e (D)urabilidade, na qual muito se pergunta se é somente durante o COMMIT que os dados que estão em memória (Database Buffer Cache) serão gravados permanentemente nos Data Files. No mais, o objetivo desse artigo será fazer um breve resumo através de um quadro comparativo para algumas dúvidas que são bem comuns em forums e grupos de discussão sobre Oracle. Dentre muitas dúvidas, listo algumas abaixo:
- Quando efetuamos COMMIT em uma transação os dados são gravados diretamente nos Data Files?
- Em que momento o processo Database Writer (DBWn) grava informações nos Data Files?
- O buffer de redo (log buffer) armazena apenas dados comitados?
- Qual o objetivo principal do processo Checkpoint (CKPT)?
- Quando alteramos uma tabela para NOLOGGING toda operação realizada na mesma não gerará nenhum dado de redo?
- Uma operação de carga direta (direct insert ou CTAS) será mais rápida em uma tabela modo NOLOGGING?
- Uma tabela no modo NOLOGGING pode se recuperar de uma falha de instância?
Bom, para começar, no banco de dados Oracle um grupo de redo é um conjunto de no mínimo dois ou mais arquivos que tem como função primária registrar todas as alterações feitas no banco de dados, incluindo as alterações com e sem commit. As entradas de redo são armazenadas temporariamente nos buffers de registro de redo (Log Buffer) da SGA (System Global Area) onde o processo de segundo plano log writer (LGWR) grava essas entradas sequencialmente em um arquivo de registro de redo online.
Estas gravações do buffer de redo para os arquivos ocorrem nas seguintes cinco situações: (1) a cada 3 segundos, (2) quando 1/3 do buffer estiver cheio, (3) quando o comando commit for emitido, (4) quando as entradas de redo no buffer atingir 1 MB, (5) antes do processo de segundo plano DBWn gravar as alterações do cache de banco de dados nos data files. Os arquivos de redo log online são utilizados de forma cíclica, por exemplo, se dois arquivos constituem o registro de redo online, o primeiro arquivo é preenchido, o segundo arquivo é preenchido, o primeiro arquivo é reutilizado e preenchido, o segundo arquivo é reutilizado e preenchido e assim por diante.
Cada vez que um arquivo é preenchido, ele recebe um número de seqüência de registro para identificar o conjunto de entradas de redo. As informações de um arquivo de redo log online são usadas apenas para proteger e recuperar o banco de dados em caso de uma falha de instância que evite que os dados em memória sejam gravados nos data files. Assim, caso uma falha evite que os dados modificados em memória (comitados) sejam gravados permanentemente nos data files, as alterações perdidas possam ser obtidas dos arquivos de redo log online através de um processo de recuperação (recover). A figura abaixo nos mostra um pouco da arquitetura de uma instância Oracle.
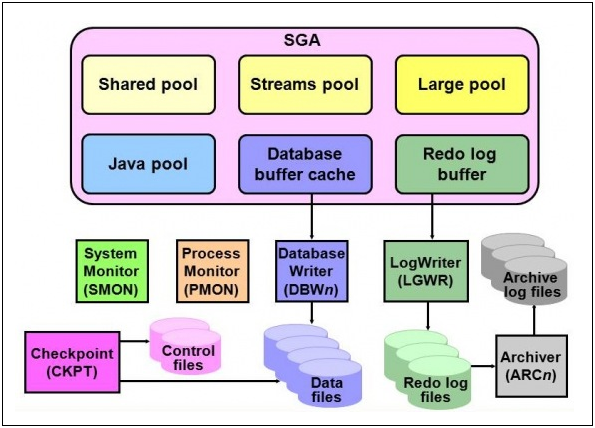
Em resumo, comitar uma transação significa apenas a garantia de sua recuperação em caso de falha, e não a gravação dos dados diretamente nos data files como muitos pensam. Esta é a 4ª propriedade dentre as conhecidas sobre segurança e integridade dos dados (ACID) que trata da DURABILIDADE e persistência das atualizações confirmadas, mesmo que haja falhas no sistema.
Em relação ao processo Checkpoint (CKPT), o mesmo ajuda a reduzir a quantidade de tempo necessário para a recuperação da instância. Durante um checkpoint, o processo CKPT atualiza o cabeçalho do control file e dos data files para refletir o último SCN (System Change Number) bem-sucedido. O processo CKPT tem como objetivo sinalizar os processos DBWn de forma que os mesmos possam gravar os buffers sujos (dirty buffers) que são aqueles blocos alterados em memória que ainda não foram gravados nos data files. Ele também atualiza os cabeçalhos dos data files e dos control files com algumas informações para que o processo SMON saiba por onde começar uma operação de recover no caso de uma queda da instância (crash recovery). A frequência com que as gravações que o processo DBWn são feitas dependem de algumas condições, mas a que mais tem influência é a métrica MTTR (Mean Time To Recovery) que pode ser alterada pelo parâmetro FAST_START_MTTR_TARGET. O valor padrão deste parâmetro é 0 (zero) e recomendo que o mesmo não seja alterado. Em relação ao Database Buffer Cache, vale a pena salientar que os buffers sujos são descarregados para os data files, independente de uma transação ser ou não comitada. Mesmo que um buffer não esteja sujo (clean buffers) isso não significa que este dado teve sua transação comitada.
Enfim, como dito anteriormente, quando ocorre COMMIT em uma transação, o log buffer é descarregado para o disco e não o buffer cache. É importante salientar que o log buffer armazena dados comitados e não comitados. O que diferencia dados comitados de não comitados no buffer log é uma marca especial chamada (Commit Marker), nada mais. Caso seja necessário a realização de um crash recovery, é através dessa marca que o Oracle saberá quais dados precisam ser aplicados nos data files (roll forward) e quais precisam ser desfeitos (roll back). Portanto, podemos perceber que poderemos ter dados comitados nos arquivos de redo log online que não estão ainda gravados nos data files e vice versa. Segue abaixo um teste para comprovar o que foi falado até aqui.
Enfim, como dito anteriormente, quando ocorre COMMIT em uma transação, o log buffer é descarregado para o disco e não o buffer cache. É importante salientar que o log buffer armazena dados comitados e não comitados. O que diferencia dados comitados de não comitados no buffer log é uma marca especial chamada (Commit Marker), nada mais. Caso seja necessário a realização de um crash recovery, é através dessa marca que o Oracle saberá quais dados precisam ser aplicados nos data files (roll forward) e quais precisam ser desfeitos (roll back). Portanto, podemos perceber que poderemos ter dados comitados nos arquivos de redo log online que não estão ainda gravados nos data files e vice versa. Segue abaixo um teste para comprovar o que foi falado até aqui.
C:\>sqlplus / as sysdba
SQL*Plus: Release 11.2.0.1.0 Production on Dom Dez 1 14:04:54 2013
Copyright (c) 1982, 2010, Oracle. All rights reserved.
Conectado a:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> create tablespace tbs_teste
2 datafile 'C:\ORACLE\ORADATA\BD01\TBS_TESTE01.DBF'
3 size 1M;
Tablespace criado.
SQL> create table emp (id varchar2(10)) tablespace tbs_teste;
Tabela criada.
SQL> insert into emp values ('VALOR1');
1 linha criada.
SQL> commit;
Commit concluído.
Acima foi criada a tabela EMP na tablespace TBS_TESTE e inserido um registro com o dado "VALOR1". Podemos ver abaixo que este dado ainda não foi gravado no data file TESTE01.DBF.
SQL> host strings -a TESTE01.DBF
Strings v2.51
Copyright (C) 1999-2013 Mark Russinovich
}|{z
BD01
TBS_TESTE
Irei agora simular um checkpoint através do comando "alter system checkpoint" e, então, poderemos ver que os dados serão descarregados do Database Buffer Cache na (SGA) para o disco, ou seja, para o data file TESTE01.DBF.
SQL> alter system checkpoint;
Sistema alterado.
SQL> host strings -a TESTE01.DBF
Strings v2.51
Copyright (C) 1999-2013 Mark Russinovich
}|{z
BD01
TESTE
VALOR1
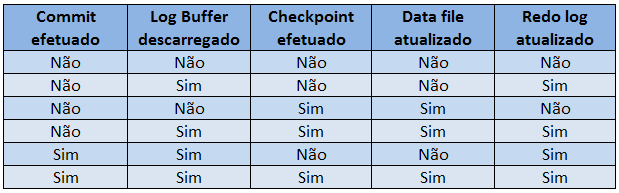
Para ajudar a guardar estes conceitos, segue abaixo um quadro comparativo dos possíveis eventos que podem ocorrer e quais arquivos sofrem gravações:
Já em relação aos modos LOGGING e NOLOGGING de uma tabela no Oracle, percebo que tem muita gente que ainda confunde ou não entende corretamente os seus conceitos. Quando criamos uma tabela e não especificamos LOGGING ou NOLOGGING, esta opção será herdada da tablespace na qual a tabela residirá. Por padrão todas as tablespaces no Oracle, exceto a TEMP são configuradas no modo LOGGING. Toda alteração DML ou DDL realizada em uma tabela no modo LOGGING será registrada nos arquivos de redo log online, ou seja, podemos dizer que a tabela está protegida e poderá ser recuperada em caso de falha da instância. Já o modo NOLOGGING minimiza a geração de dados de redo para algumas operações.
Tenho a impressão que muitas pessoas têm a percepção de que o modo NOLOGGING elimina completamente a geração de redo para todas as operações DML (insert, delete, merge, update). Isto não está correto. O modo NOLOGGING não afeta a geração de redo para uma operação INSERT regular, DELETE, MERGE e UPDATE. Em relação à operações DML, somente operações de INSERT de carga direta (direct path insert) tiram vantagens enquanto uma tabela está no modo NOLOGGING. A velocidade do INSERT é maior exatamente por ter uma minimização na geração de redo. A desvantagem é que em caso de alguma falha da instância, a operação não poderá ser recuperada. Portanto, recomenda-se que o seu uso seja restrito para operações na qual a perda de dados possa ser aceita, ou seja, se o dado é crítico, não use o modo NOLOGGING. Nada impede também que um backup seja realizado após a carga de dados. Em relação a velocidade do INSERT, veja a demonstração abaixo usando o método CTAS utilizando como fonte dos dados a tabela (EMP) com aproximadamente 16 milhões de registros:
SQL> set timing on
SQL> create table t1_dados_logging as select * from emp;
Tabela criada.
Decorrido: 00:00:39.76
SQL> create table t1_dados_nologging NOLOGGING as select * from emp;
Tabela criada.
Decorrido: 00:00:21.28
Podemos ver acima que a diferença foi de 18 segundos. Para grandes cargas a diferença poderá ser de muitas horas. Houve uma vez que eu consegui diminuir o tempo de carga em uma rotina de 12 horas para 3 horas, apenas adicionando a cláusula NOLOGGING na criação da tabela ao usar o método CTAS.
Em resumo, seguem abaixo algumas operações que tiram vantagem em relação à performance no modo NOLOGGING:
- Direct Load INSERT (através do hint APPEND)
- DIRECT LOAD (SQL*Loader)
- CREATE TABLE ... AS SELECT
- CREATE INDEX
- ALTER TABLE MOVE
- ALTER TABLE ... MOVE PARTITION
- ALTER TABLE ... SPLIT PARTITION
- ALTER TABLE ... ADD PARTITION
- ALTER TABLE ... MERGE PARTITION
- ALTER TABLE ... MODIFY PARTITION
- ALTER INDEX ... SPLIT PARTITION
- ALTER INDEX ... REBUILD
- ALTER INDEX ... REBUILD PARTITION
Para comprovar que menos dado de redo é gerado, veja o exemplo abaixo na qual utilizo o hint APPEND durante a inserção de dados em uma tabela criada como NOLOGGING:
SQL> create table t1_dados_nologging (id number) NOLOGGING;
Tabela criada.
SQL> select name,value as redo1 from v$sysstat where name='redo size';
NAME REDO1
----------------------- ---------
redo size 882169876
SQL> insert into t1_dados_nologging select * from emp;
16777216 linhas criadas.
SQL> select name,value as redo2 from v$sysstat where name='redo size';
NAME REDO2
----------------------- ----------
redo size 1110731824
SQL> insert /*+ APPEND */ into t1_dados_nologging select * from emp;
16777216 linhas criadas.
SQL> select name,value as redo3 from v$sysstat where name='redo size';
NAME REDO3
----------------------- ----------
redo size 1110819664
No exemplo acima, podemos notar que o redo gerado no primeiro insert foi de 228.561.948 (REDO2 - REDO1), enquanto que no insert utilizando o hint APPEND (direct insert) foi de apenas 87.840 (REDO3 - REDO2), ou seja, um mínimo de redo foi gerado.
No mais, vale a pena salientar que se um banco de dados estiver operando no modo NOARCHIVELOG, então para cargas diretas (Direct Path Insert), alterar uma tabela para o modo NOLOGGING se torna desnecessário. Segue abaixo um quadro comparativo das operações envolvidas para cada tipo de cenário:

Por fim, caso uma falha de mídia ocorra após uma tabela no modo NOLOGGING ter sido populada e nenhum backup tenha sido realizado após essa carga de dados, após a operação de recovery e abertura do banco de dados, poderemos verificar a presença do erro abaixo:
SQL> select count(*) from T1_DADOS_NOLOGGING;
select count(*) from T1_DADOS_NOLOGGING
*
ERRO na linha 1:
ORA-01578: bloco de dados ORACLE danificado (arquivo núm. 1, bloco núm. 31913)
ORA-01110: 1 do arquivo de dados: 'C:\ORACLE\ORADATA\BD02\SYSTEM01.DBF'
ORA-26040: O bloco de dados foi carregado por intermédio da opção NOLOGGING












16 comentários:
Muito obrigado pelos ótimos artigos...estou aprendendo muito..parabéns.
Marcelo Lima
Olá Marcelo,
Obrigado pela visita!!
Abraços e até mais ...
Legatti
Oi Eduardo,
Uma dúvida, gravações do buffer de redo para os arquivos ocorrem nas seguintes cinco situações: (5) antes do processo de segundo plano DBWn gravar as alterações do cache de banco de dados nos data files.
Quando diz que sempre quando ocorre o processo DBWn acontece uma gravação no arquivo redo log on line.
Com isso a tabela que mostrou para facilitar o aprendizado teria q ter um "sim" para redo log atualizado sempre quando tiver "sim" para datafile atualizado.
Olá Rodrigo,
Sua dúvida é pertinente. As gravações do buffer de redo (log buffer) são gravados nos arquivos de redo do log online geralmente nesses 5 casos. No entanto, não é toda vez que um data file é atualizado que o redo log file também foi atualizado (sequencialmente nessa ordem). Existe tanto checkpoints completos como checkpoints incrementais, entre outros, que podem acontecer em momentos específicos. Em um desses casos pode ocorrer a descarga do log buffer para os redo log files antes do DBWn gravar nos data files. No mais, a intenção do quadro é resumir e facilitar a compreensão dos eventos, mostrando que o log buffer quando descarregado, atualiza os redo log files, e quando um checkpoint ocorre, os data files é que são atualizados independentemente do COMMIT de uma transação.
Talvez um quadro que tivesse a relação de todos os eventos possíveis junto com todos os processos background envolvidos (CKPT, DBWn, LGWR) pudesse tirar a sua dúvida de forma mais precisa. No entanto iria ser um quadro bastante complexo ;-)
Abraços e até mais
Legatti
Sem palavras para dizer o quanto esse arquivo é sensacional...aprendo muito aqui no seu blog, parabéns e continue postando.
Olá Diogenes,
Obrigado pelo seu comentário e pela visita ;-)
Abraços e até mais
Legatti
Legatti,
Sensacional!!!
Obrigado.
Olá Unknown,
Obrigado pela visita!
Abraços
Legatti
Amigo, gostei muito do artigo acima. Tenho um dúvida :- é possível efetuar um select em dados ainda não comitados ( transação aberta ) ?
Grato
Dinísio
Olá Dionísio,
Os níveis de isolamento disponibilizados no Oracle são READ COMMITTED e SERIALIZABLE. O nível de isolamento READ UNCOMMITED não é suportado pelo Oracle, então oficialmente não tem como ler dados não comitados de outras sessões.
Abraços e até mais
Legatti
Ou seja, caso não tenha feito o backup após a carga da tabela no modo nologging mesmo que o banco de dados esteja operando no modo archivelog, não será possível recuperar o dado caso ocorra falha de mídia. Certo Eduardo?
select count(*) from T1_DADOS_NOLOGGING
*
ERRO na linha 1:
ORA-01578: bloco de dados ORACLE danificado (arquivo núm. 1, bloco núm. 31913)
ORA-01110: 1 do arquivo de dados: 'C:\ORACLE\ORADATA\BD02\SYSTEM01.DBF'
ORA-26040: O bloco de dados foi carregado por intermédio da opção NOLOGGING
Att,
Rodrigo
Olá Rodrigo,
Correto. Todas as tentativas de recuperar a tabela foram mal sucedidas, mesmo o banco operando em archivelog.
Abraços,
Legatti
Eduardo, Ótimo artigo !
Eu testei este recurso em 3 databases diferentes, todos em ARCHIVELOG, utilizando uma tabela NOLOGGING + APPEND e a quantidade de redo não diminui.
Ainda não entendi por que isto está acontecendo, comportamento bizarro.
Segue evidencia:
SQL> create table logging_example nologging as select * from dba_objects where 1=2;
Table created.
SQL> set autotrace on statistics
SQL> set timing on
SQL> alter system flush buffer_cache;
System altered.
Elapsed: 00:00:00.10
SQL> insert into logging_example select * from dba_objects;
73341 rows created.
Elapsed: 00:00:02.37
Statistics
----------------------------------------------------------
95 recursive calls
12160 db block gets
20200 consistent gets
1796 physical reads
11728112 redo size
858 bytes sent via SQL*Net to client
974 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
73341 rows processed
SQL> alter system flush buffer_cache;
System altered.
Elapsed: 00:00:00.07
SQL> insert /*+ append */ into logging_example select * from dba_objects;
73341 rows created.
Elapsed: 00:00:01.39
Statistics
----------------------------------------------------------
193 recursive calls
1904 db block gets
19479 consistent gets
1813 physical reads
11795516 redo size
846 bytes sent via SQL*Net to client
989 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
73341 rows processed
Abraço !
Olá,
É porque ele está acumulando na sua sessão.
11795516 - 11728112 = 67404
Então o segundo insert gerou apenas 67404 de redo.
Abraços,
Legatti
Eduardo, obrigado por esclarece minha duvida anterior, mas acho que minha duvida está em compreender os valores retornados em v$mystat em relação ao explain, qual a relação destes valores, pois em ambos, são retornados valores diferentes e ambos são cumulativos, confesso que não consegui extrair a diferença entre um e outro, não consegui isolar a diferença de ambos os SQLs, observando os dados a partir da view v$mystat.
SQL> SELECT
sn.name,
ss.value
FROM
v$mystat ss,
v$statname sn
WHERE
ss.statistic# = sn.statistic#
AND sn.name IN ('redo size'); 2 3 4 5 6 7 8 9
NAME VALUE
---------------------------------------------------------------- ----------
redo size 0
SQL> set autotrace on statistics
SQL> insert into logging_example select * from all_objects;
72112 rows created.
Statistics
----------------------------------------------------------
246 recursive calls
12027 db block gets
23534 consistent gets
0 physical reads
11563284 redo size
839 bytes sent via SQL*Net to client
974 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
72112 rows processed
SQL> SELECT
sn.name,
ss.value
FROM
v$mystat ss,
v$statname sn
WHERE
ss.statistic# = sn.statistic#
AND sn.name IN ('redo size'); 2 3 4 5 6 7 8 9
NAME VALUE
---------------------------------------------------------------- ----------
redo size 11563284
SQL> insert /*+ append */ into logging_example select * from dba_objects;
73340 rows created.
Statistics
----------------------------------------------------------
220 recursive calls
1912 db block gets
19544 consistent gets
0 physical reads
11797004 redo size
844 bytes sent via SQL*Net to client
988 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
73340 rows processed
SQL> SELECT
sn.name,
ss.value
FROM
v$mystat ss,
v$statname sn
WHERE
ss.statistic# = sn.statistic#
AND sn.name IN ('redo size'); 2 3 4 5 6 7 8 9
NAME VALUE
---------------------------------------------------------------- ----------
redo size 23360288
Abs
Olá,
No exemplo do artigo eu foquei apenas na geração do redo. Os outros valores não entraram em questão.
Abraços
Legatti
Postar um comentário