Olá,
Fazendo um complemento relacionando ao artigo de 08/2022 MongoDB - Benchmark de Performance (3.2 a 6.0), incluí as versões 7.0 e 8.0 do MongoDB ao Benchmark.

Olá,
Fazendo um complemento relacionando ao artigo de 08/2022 MongoDB - Benchmark de Performance (3.2 a 6.0), incluí as versões 7.0 e 8.0 do MongoDB ao Benchmark.
Olá,
À medida que o mundo da tecnologia da informação continua a evoluir, novas funções e especializações surgem para atender às demandas complexas do gerenciamento de dados. Três papéis cruciais que frequentemente geram confusão são os de Database Reliability Engineer (DBRE), Database Administrator (DBA) e Cientista de Dados. Vamos explorar suas diferenças e compreender como esses profissionais contribuem para o ecossistema de dados.

Database Reliability Engineer (DBRE): A Ponte Entre Desenvolvimento e Operações
O DBRE é um profissional que se concentra na confiabilidade e eficiência dos bancos de dados. Sua função é garantir que os sistemas de gerenciamento de banco de dados (DBMS) estejam sempre disponíveis, resilientes e otimizados. Eles atuam como uma ponte entre desenvolvedores e equipes de operações, garantindo que as aplicações se integrem harmoniosamente aos bancos de dados sejam eles banco de dados relacionais ou NOSQL.
Principais responsabilidades do DBRE:
Database Administrator (DBA): Guardião dos Dados e Estruturas do Banco de Dados
Enquanto o DBRE se concentra na confiabilidade, o DBA é o guardião dos dados e da estrutura do banco de dados. Eles desempenham um papel vital na criação, manutenção e otimização de esquemas de banco de dados, garantindo a integridade e segurança dos dados armazenados.
Principais responsabilidades do DBA:
Cientista de Dados: Transformando Dados em Insights Estratégicos
Os Cientistas de Dados são responsáveis por extrair insights valiosos a partir de conjuntos de dados. Envolvem-se em análise estatística, machine learning e modelagem preditiva para ajudar as organizações a tomar decisões informadas.
Principais responsabilidades do Cientista de Dados:
Em resumo, enquanto o DBRE e o DBA garantem a integridade, confiabilidade e eficiência dos bancos de dados, o Cientista de Dados utiliza esses dados para gerar valor estratégico. Juntos, esses profissionais formam uma equipe essencial para o gerenciamento eficaz de dados em um ambiente tecnológico em constante evolução.
Olá,
O ElasticSearch é um mecanismo de busca e análise distribuído de código aberto, que permite realizar pesquisas em tempo real em grandes conjuntos de dados. Ele é construído sobre o Apache Lucene e permite que os usuários realizem pesquisas de texto completo, análise de dados e métricas. Ele é construído sobre o Apache Lucene, um mecanismo de pesquisa de código aberto e é projetado para ser altamente escalável e distribuído, permitindo que os usuários executem pesquisas em grandes conjuntos de dados em tempo real.
O ElasticSearch é composto por um cluster de nós, com cada nó armazenando e indexando dados. Ele usa o conceito de shards, que são partições dos dados, que são distribuídas pelos nós no cluster.
Uma shard é basicamente um fragmento de um índice que contém uma parte dos dados indexados e os documentos associados a esses dados. Cada shard é um índice separado, com seu próprio conjunto de documentos e metadados. Os shards são distribuídos entre os nós do cluster, permitindo que a pesquisa seja distribuída e escalável.
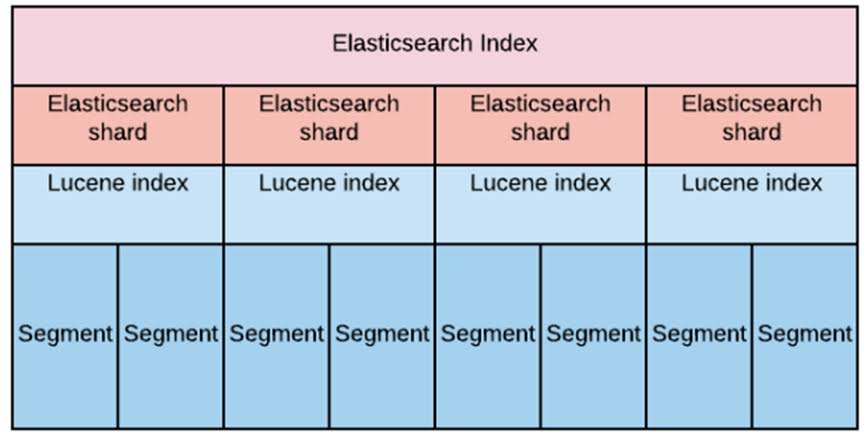
Existem dois tipos de shards no Elasticsearch: shards primárias e réplicas de shards. Uma shard primária é a shard que contém a fonte de dados e os documentos associados. Cada documento é armazenado em uma shard primária. As réplicas de shard são cópias de uma shard primária e são usadas para garantir a disponibilidade e a recuperação de desastres. A configuração do número de shards e réplicas em um índice é importante para o desempenho e escalabilidade do cluster. É importante equilibrar o número de shards e réplicas com a capacidade de hardware do cluster. Configurar um número excessivo de shards pode afetar o desempenho do cluster, pois cada shard consome recursos de hardware e pode aumentar o tempo de recuperação de desastres.

Um cluster de Elasticsearch consiste em vários nós que trabalham juntos para armazenar e pesquisar dados. Como exemplo, dois tipos de nós no Elasticsearch são o master node e o data node. De modo bem simples, na imagem abaixo irei chamar os data nodes de Slave Nodes.
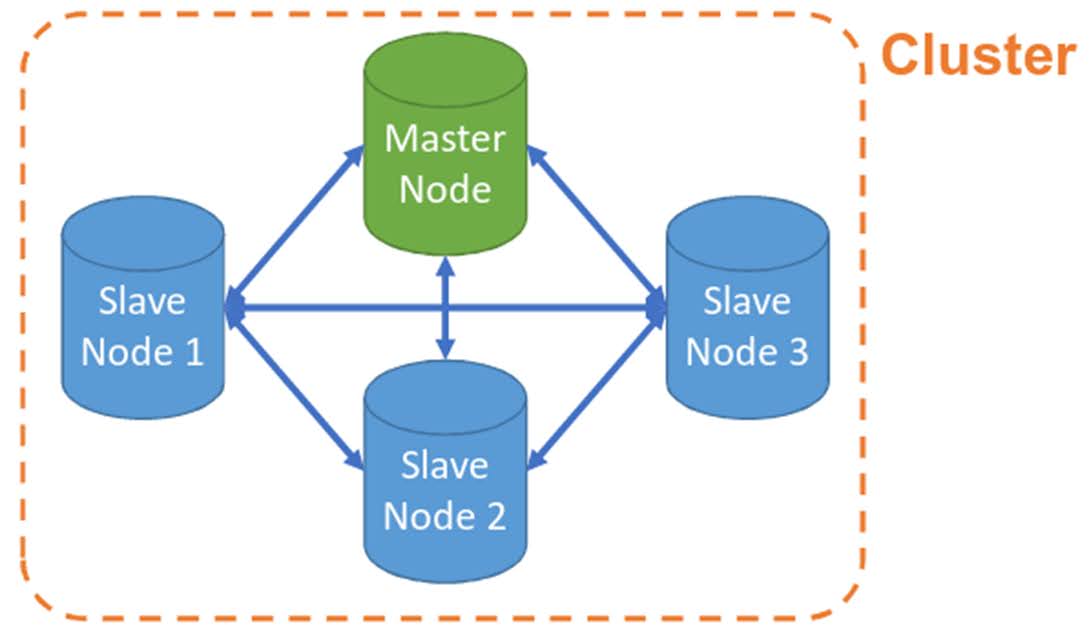
O master node é responsável por gerenciar o cluster e coordenar as atividades de todos os outros nós do cluster. Ele é responsável por atribuir shards primárias a nós de dados disponíveis, monitorar a saúde do cluster e gerenciar a configuração do cluster. O master node é crucial para garantir a disponibilidade e a integridade dos dados no cluster.
Os data nodes são os nós que armazenam e manipulam os dados. Eles são responsáveis por indexar, armazenar e recuperar os dados. Eles também gerenciam as réplicas de shards que são distribuídas em todo o cluster. Os data nodes são otimizados para armazenamento e processamento de dados e são responsáveis por executar operações de pesquisa e análise em grande escala.
É importante entender a diferença entre os nós de dados e os nós de master no Elasticsearch. Os nós de dados são responsáveis pelo armazenamento e processamento dos dados, enquanto os nós de master gerenciam o cluster e atribuem as shards primárias a nós de dados disponíveis. A separação dessas funções ajuda a garantir que o cluster possa lidar com grandes volumes de dados e mantém a integridade dos dados.
Em um cluster típico de Elasticsearch, é comum ter vários nós de dados e no mínimo três nós de master. Há casos também em clusters pequenos onde os nós são master e data ao mesmo tempo. Ter vários nós de dados permite que o cluster lide com grandes volumes de dados e forneça alta disponibilidade de dados. Ter três nós de master fornece redundância e ajuda a evitar pontos únicos de falha no gerenciamento do cluster.

Para garantir o bom desempenho e escalabilidade de um cluster Elasticsearch, existem algumas práticas recomendadas que podem ser seguidas:
Seguindo essas práticas recomendadas, você pode garantir que seu cluster Elasticsearch tenha desempenho ideal, seja escalável e tenha alta disponibilidade. Além disso, é importante manter-se atualizado sobre as atualizações e recursos do Elasticsearch e implementar essas práticas recomendadas de forma consistente para garantir o sucesso do seu cluster.
Olá,
No artigo de Agosto/2022 eu realizei um benchmark de performance entre as versões do MongoDB. Neste artigo irei realizar uma comparação de performance do MongoDB nas arquiteturas ARM e X86 nas instâncias EC2 da AWS.
Como introdução, vale a pena salientar que a arquitetura de processadores é um assunto importante para entender a diferença entre diferentes tipos de dispositivos, especialmente quando se trata de escolher entre dispositivos móveis, como smartphones e tablets, e computadores desktop ou portáteis. As duas arquiteturas mais comuns são a ARM (Advanced RISC Machines) e a x86, que são usadas em dispositivos diferentes com objetivos diferentes.
A arquitetura ARM é amplamente utilizada em dispositivos móveis, como smartphones e tablets. É uma arquitetura de processadores RISC (Reduced Instruction Set Computing), o que significa que ela usa menos instruções do que outras arquiteturas, como x86. Isso permite que os processadores ARM sejam mais eficientes em termos de consumo de energia e, consequentemente, permitem que os dispositivos móveis tenham uma vida útil de bateria mais longa. Além disso, os processadores ARM são geralmente mais baratos e mais leves do que os processadores x86.
A arquitetura x86, por outro lado, é amplamente utilizada em computadores desktop e portáteis. É uma arquitetura de processadores CISC (Complex Instruction Set Computing), o que significa que ela usa mais instruções do que a arquitetura ARM. Isso significa que os processadores x86 são geralmente mais poderosos do que os processadores ARM, mas também são mais consumidores de energia. Além disso, os processadores x86 geralmente são mais caros e mais pesados do que os processadores ARM.
A performance em servidores de banco de dados é importante para garantir que as aplicações que dependem desses bancos de dados funcionem de maneira eficiente e rápida. Aqui estão alguns exemplos de como a arquitetura de processador pode afetar a performance em servidores de banco de dados:
Em resumo, a escolha da arquitetura de processador para um servidor de banco de dados dependerá do equilíbrio entre taxa de transferência de dados, processamento de dados, escalabilidade e consumo de energia. Se a prioridade for o processamento de dados rápido, a arquitetura x86 é uma boa escolha. Se a prioridade for a eficiência energética, a arquitetura ARM é uma boa escolha.
A Amazon Web Services (AWS) oferece servidores EC2 com duas arquiteturas diferentes: ARM e x86. Aqui estão alguns exemplos de uso dessas arquiteturas para bancos de dados:
Arquitetura ARM:
A EC2 A1 e M6g oferece processadores ARM-based Graviton2, que são projetados especificamente para a nuvem e têm uma arquitetura de baixo consumo de energia. Isso significa que as instâncias A1 são mais econômicas em termos de custo por hora de operação em comparação com as instâncias x86. Além disso, as instâncias A1 são otimizadas para carregar altas cargas de trabalho de I/O, o que as torna ideais para bancos de dados NoSQL que exigem alta escalabilidade horizontal.
Entretanto, é importante lembrar que a compatibilidade de software é uma questão importante a se considerar ao escolher a arquitetura ARM. Alguns softwares, como os bancos de dados relacionais, podem não ser compatíveis com a arquitetura ARM e, portanto, exigirão ajustes adicionais para funcionar corretamente.
Arquitetura x86:
A EC2 M5, R5 e M6i oferece processadores Intel Xeon Scalable, que são amplamente utilizados em aplicações empresariais e de nuvem. Isso significa que a compatibilidade de software é geralmente mais ampla em comparação com a arquitetura ARM.
Além disso, as instâncias R5 são projetadas para fornecer recursos adicionais, como CPU, memória e armazenamento, para lidar com operações complexas de consulta e processamento de dados. Isso as torna ideais para bancos de dados relacionais que exigem alta performance de processamento. No entanto, é importante lembrar que as instâncias x86 tendem a ser mais caras em termos de custo por hora de operação em comparação com as instâncias ARM. Além disso, as instâncias x86 podem consumir mais energia em comparação com as instâncias ARM, o que pode afetar a eficiência energética da sua solução de banco de dados.
Em resumo, a escolha entre a arquitetura ARM e x86 para seu banco de dados na AWS dependerá de suas necessidades específicas em termos de desempenho, custo e compatibilidade de software.
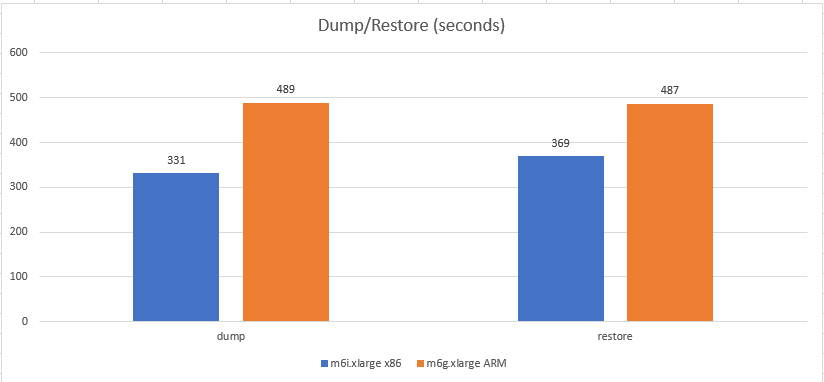
Segue abaixo o comparativo de performance utilizando o MongoDB nas instâncias M6i.xlarge (X86) e M6g.xlarge (ARM) na qual foram executadas operações no MongoDB durante 4 horas ininterruptas.