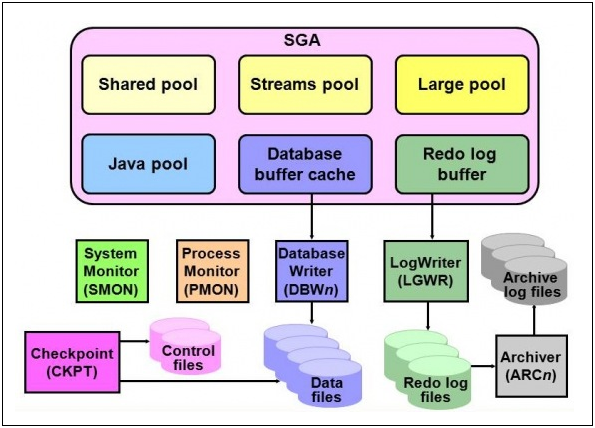
Olá,
No artigo de Novembro/2008 eu abordei o uso do objeto SEQUENCE, disponível no banco de dados Oracle, com o objetivo de simular a criação de colunas do tipo auto-incremento. Realmente, até a versão 11g, o Oracle não possui um tipo de dado auto-incremento, mas, no Oracle 12c, isso mudou. Neste artigo irei abordar duas novas características que foram implementadas no Oracle 12c e mencionadas no artigo de Junho/2013.
- No Oracle 12c é possível especificar as pseudo-colunas CURRVAL e NEXTVAL de uma sequence como valor DEFAULT para uma coluna de uma tabela.
- No Oracle 12c existe suporte à colunas do tipo auto-incremento (IDENTITY).
Utilizando valores DEFAULT com SEQUENCES de banco de dados
Até a versão 11g, o Oracle não permite definir um objeto SEQUENCE na cláusula DEFAULT de uma coluna de tabela, como demonstrado abaixo:
C:\>sqlplus scott/tiger
SQL*Plus: Release 11.2.0.1.0 Production on Qua Out 2 19:00:08 2013
Copyright (c) 1982, 2010, Oracle. All rights reserved.
Conectado a:
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> create sequence seq_teste nocache;
Seqüência criada.
SCOTT> desc minha_tabela
Nome Nulo? Tipo
---------------------- -------- ----------------------
ID NOT NULL NUMBER
DESCRICAO NOT NULL VARCHAR2(100)
SQL> alter table minha_tabela modify id DEFAULT SEQ_TESTE.NEXTVAL;
alter table minha_tabela modify id DEFAULT SEQ_TESTE.NEXTVAL
*
ERRO na linha 1:
ORA-00984: coluna não permitida aqui
À partir do Oracle 12c, é possível especificar uma SEQUENCE de banco de dados e utilizar as pseudo-colunas NEXTVAL e CURRVAL na cláusula DEFAULT de uma coluna de tabela como demonstrado abaixo:
C:\>sqlplus scott/tiger
SQL*Plus: Release 12.1.0.1.0 Production on Qua Out 2 19:03:54 2013
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Horário do último log-in bem-sucedido: Qua Out 2 2013 18:54:03 -03:00
Conectado a:
Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production
With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options
SQL> create sequence seq_teste nocache;
Sequência criada.
SQL> create table minha_tabela (
2 id number constraint pk_minha_tabela primary key,
3 nome varchar2(60) not null);
Tabela criada.
SQL> alter table minha_tabela modify id DEFAULT SEQ_TESTE.NEXTVAL;
Tabela alterada.
SQL> select table_name,
2 column_name,
3 data_default
4 from user_tab_columns
5 where table_name='MINHA_TABELA';
TABLE_NAME COLUMN_NAME DATA_DEFAULT
------------------- ---------------- -----------------------------
MINHA_TABELA ID "SCOTT"."SEQ_TESTE"."NEXTVAL"
MINHA_TABELA NOME
SQL> insert into minha_tabela (nome) values ('Nome_1');
1 linha criada.
SQL> insert into minha_tabela (nome) values ('Nome_2');
1 linha criada.
SQL> insert into minha_tabela (nome) values ('Nome_3');
1 linha criada.
SQL> select * from minha_tabela order by 1;
ID NOME
---------- -----------------------------------------
1 Nome_1
2 Nome_2
3 Nome_3
SQL> insert into minha_tabela values (10,'Nome_10');
1 linha criada.
SQL> select * from minha_tabela order by 1;
ID NOME
---------- -----------------------------------------
1 Nome_1
2 Nome_2
3 Nome_3
10 Nome_10
No exemplo acima, podemos ver que é possível inserir uma valor de ID explícito, como por exemplo ID=10. Vale a pena salientar que, caso a coluna aceite valores nulos, e um valor NULL for inserido, então o valor DEFAULT não será utilizado. Para que isso não aconteça, a coluna deverá ser criada utilizando a cláusula ON NULL conforme exemplo do comando abaixo:
create table t1 (
id number DEFAULT ON NULL SEQ_TESTE.NEXTVAL,
nome varchar(10)
);
No mais, vale a pena salientar que, se tentarmos droparmos a sequence, o Oracle não irá fazer uma verificação de dependência entre a tabela e a sequence, ou seja, conseguiremos dropar a sequence sem o menor problema. Consequentemente, as operações de INSERT irão falhar com a emissão do erro ORA-02289 conforme demonstração abaixo:
SQL> drop sequence seq_teste;
Sequência eliminada.
SQL> insert into minha_tabela (nome) values ('Nome_4');
insert into minha_tabela (nome) values ('Nome_4')
*
ERRO na linha 1:
ORA-02289: a sequência não existe
Colunas do tipo auto-incremento (IDENTITY)
Uma outra novidade do Oracle 12c se refere à possibilidade de criar colunas do tipo auto-incremento. Na minha visão, não foi criado um novo tipo de dado (DATA TYPE) no Oracle, e sim uma engenharia interna que oferece esse recurso. A figura abaixo mostra as novas cláusulas que poderão ser utilizadas na criação de uma coluna em uma tabela:
Segue abaixo alguns exemplos práticos dos tipos de coluna IDENTITY que poderemos criar à partir do Oracle 12c. Como primeiro exemplo, podemos perceber abaixo que ao criar uma tabela contendo uma coluna IDENTITY, será necessário que o owner da tabela tenha o privilégio de sistema CREATE SEQUENCE.
SQL> create table t1_always (
2 id number GENERATED ALWAYS AS IDENTITY,
3 nome varchar2(20)
4 );
create table t1_always (
*
ERRO na linha 1:
ORA-01031: privilégios insuficientes
SQL> select * from session_privs;
PRIVILEGE
----------------------------------------
SET CONTAINER
CREATE TABLE
CREATE SESSION
SQL> connect / as sysdba
Conectado.
SQL> grant create sequence to scott;
Concessão bem-sucedida.
SQL> connect scott/tiger
Conectado.
SQL> create table t1_always (
2 id number GENERATED ALWAYS AS IDENTITY,
3 nome varchar2(20)
4 );
Tabela criada.
SQL> desc t1_always
Nome Nulo? Tipo
----------------- -------- -----------------------
ID NOT NULL NUMBER
NOME VARCHAR2(20)
Podemos notar pelo resultado do comando DESCRIBE acima, que uma coluna IDENTITY é obrigatória (NOT NULL). Abaixo podemos ver que o Oracle automaticamente criou uma SEQUENCE de banco de dados com o nome de ISEQ$$_19860.
SQL> select sequence_name,
2 increment_by,
3 cache_size,
4 last_number
5 from user_sequences;
SEQUENCE_NAME INCREMENT_BY CACHE_SIZE LAST_NUMBER
----------------- ------------ ---------- -----------
ISEQ$$_19860 1 20 1
Se por acaso tentarmos dropar essa SEQUENCE, o Oracle irá emitir o erro ORA-32794, ou seja, diferentemente de especificar uma SEQUENCE como DEFAULT em uma coluna, onde não há qualquer dependência entre a SEQUENCE e a coluna da tabela, no caso de uma coluna do tipo IDENTITY a SEQUENCE que é criada automaticamente faz parte dessa engenharia.
SQL> drop sequence ISEQ$$_19860;
drop sequence ISEQ$$_19860
*
ERRO na linha 1:
ORA-32794: não é possível eliminar uma sequência gerada pelo sistema
Consultado as views DBA/ALL/USER_TAB_COLUMNS podemos identificar as colunas que são do tipo IDENTITY conforme demonstrado abaixo:
SQL> select table_name,column_name,data_default,identity_column from user_tab_columns;
TABLE_NAME COLUMN_NAME DATA_DEFAULT IDE
------------ ------------- ------------------------------- ---
T1_ALWAYS ID "SCOTT"."ISEQ$$_19860".NEXTVAL YES
T1_ALWAYS NOME NO
No mais, segue abaixo os tipos de colunas IDENTITY que poderemos criar à partir do Oracle 12c.
GENERATED ALWAYS AS IDENTITY
Uma coluna IDENTITY criada com a cláusula ALWAYS sempre irá forçar a geração do valor sequencial. Caso algum valor seja informado na coluna IDENTITY, o erro ORA-32795 será emitido.
SQL> create table t1_always (
2 id number GENERATED ALWAYS AS IDENTITY,
3 nome varchar2(20)
4 );
Tabela criada.
SQL> insert into t1_always values (1,'teste1');
insert into t1_always values (1,'teste1')
*
ERRO na linha 1:
ORA-32795: não é possível inserir em uma coluna de identidade sempre gerada
SQL> insert into t1_always (nome) values ('teste1');
1 linha criada.
SQL> select * from t1_always;
ID NOME
---------- --------------------
1 teste1
SQL> insert into t1_always (nome)
2 select 'teste'||level from dual
3 connect by level <= 10;
10 linhas criadas.
SQL> select * from t1_always;
ID NOME
---------- --------------------
1 teste1
2 teste1
3 teste2
4 teste3
5 teste4
6 teste5
7 teste6
8 teste7
9 teste8
10 teste9
11 teste10
11 linhas selecionadas.
GENERATED BY DEFAULT AS IDENTITY
Uma coluna IDENTITY criada com a cláusula BY DEFAULT não irá forçar a geração do valor sequencial, ou seja, caso algum valor seja informado na coluna IDENTITY, o mesmo será inserido ao invés do valor sequencial.
SQL> create table t2_by_default (
2 id number GENERATED BY DEFAULT AS IDENTITY,
3 nome varchar2(20)
4 );
Tabela criada.
SQL> insert into t2_by_default (nome) values ('teste1');
1 linha criada.
SQL> insert into t2_by_default values (11,'teste11');
1 linha criada.
SQL> select * from t2_by_default;
ID NOME
---------- --------------------
1 teste1
11 teste11
GENERATED BY DEFAULT ON NULL AS IDENTITY
Uma coluna IDENTITY criada com a cláusula BY DEFAULT ON NULL não irá forçar a geração do valor sequencial, ou seja, caso algum valor seja informado na coluna IDENTITY, o mesmo será inserido ao invés do valor sequencial. Caso NULL seja informado, então o valor sequencial será gerado para a coluna.
SQL> create table t3_by_default_on_null (
2 id number GENERATED BY DEFAULT ON NULL AS IDENTITY,
3 nome varchar2(20)
4 );
Tabela criada.
SQL> insert into t3_by_default_on_null (nome) values ('teste1');
1 linha criada.
SQL> insert into t3_by_default_on_null (id,nome) values (11,'teste11');
1 linha criada.
SQL> insert into t3_by_default_on_null (id,nome) values (NULL,'teste200');
1 linha criada.
SQL> select * from t3_by_default_on_null;
ID NOME
---------- --------------------
1 teste1
11 teste11
2 teste200
Por fim, poderemos utilizar a view de dicionário de dados DBA/ALL/USER_TAB_IDENTITY_COLS para visualizar todas as tabelas que possuem colunas do tipo IDENTITY, conforme demonstrado abaixo:
SQL> select table_name,
2 column_name,
3 generation_type,
4 identity_options
5 from user_tab_identity_cols;
TABLE_NAME COLUMN_NAME GENERATION IDENTITY_OPTIONS
----------------------- ----------- ----------- ----------------------------------------
T1_ALWAYS ID ALWAYS START WITH: 1, INCREMENT BY: 1, MAX_VALU
E: 9999999999999999999999999999, MIN_VAL
UE: 1, CYCLE_FLAG: N, CACHE_SIZE: 20, OR
DER_FLAG: N
T2_BY_DEFAULT ID BY DEFAULT START WITH: 1, INCREMENT BY: 1, MAX_VALU
E: 9999999999999999999999999999, MIN_VAL
UE: 1, CYCLE_FLAG: N, CACHE_SIZE: 20, OR
DER_FLAG: N
T3_BY_DEFAULT_ON_NULL ID BY DEFAULT START WITH: 1, INCREMENT BY: 1, MAX_VALU
E: 9999999999999999999999999999, MIN_VAL
UE: 1, CYCLE_FLAG: N, CACHE_SIZE: 20, OR
DER_FLAG: N