Em artigos anteriores como os de Fevereiro/2011, Abril/2011 e Junho/2011 apresentei uma visão geral sobre tabelas particionadas. A idéia deste artigo é demonstrar os tipos de índices que podemos criar sobre as tabelas particionadas, como os índices particionados globais e locais, além dos índices globais não particionados.
Bom, de forma geral, o objetivo de um índice é permitir acesso mais rápido às linhas de uma tabela. Um índice armazena o valor da coluna ou colunas que estão sendo indexadas, junto com o ROWID da linha que contém o valor indexado. A figura abaixo representa um índice comum ou regular (Btree) criado sobre uma tabela não particionada.

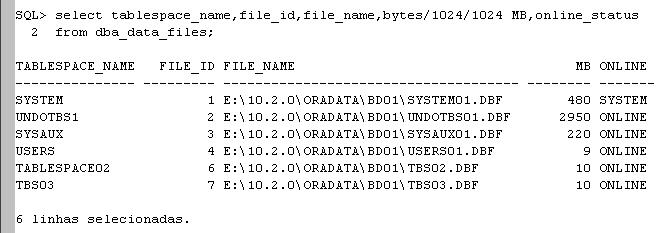
Em se tratando de tabelas particionadas, podemos criar índices locais e globais, ambos particionados e também poderemos criar índices globais não particionados. Para este artigo criarei a tabela T1 particionada por faixa (RANGE) como demonstrado abaixo:
SQL> create table t1
2 (id number,
3 cod number)
3 tablespace users
4 partition by range(id)
5 (
6 partition pdezenas values less than (100) tablespace tbs_dezenas,
7 partition pcentenas values less than (1000) tablespace tbs_centenas,
8 partition pmilhares_1000 values less than (2000) tablespace tbs_milhares,
9 partition pmilhares_2000 values less than (3000) tablespace tbs_milhares,
10 partition pmilhares_3000 values less than (4000) tablespace tbs_milhares,
11 partition pmilhares_4000 values less than (5000) tablespace tbs_milhares,
12 partition pmilhares_n values less than (maxvalue) tablespace tbs_milhares
13 );
Tabela criada.
Bom, os índices particionados locais refletem a estrutura da tabela particionada e são particionados de forma igual a tabela particionada subjacente, ou seja, eles são particionados nas mesmas colunas que a tabela e, portanto, tem os mesmos números de partições e os mesmos limites (HIGH_VALUE) que a tabela particionada. Vale a pena salientar que as partições de índices recebem o mesmo nome das partições de tabela. Um dos benefícios dos índice locais é a sua afinidade com a tabela subjacente, pois quando uma nova partição é criada, a partição de índice correspondente é criada automaticamente. Da mesma maneira, ao dropar uma partição da tabela, a partição de índice também é dropada automaticamente sem invalidar quaisquer outras partições de índice, como seria no caso de um índice global. A figura abaixo representa um índice particionado localmente.

SQL> create index idx_t1_local on t1 (id) local;
Índice criado.
SQL> select index_name,
2 partition_name,
3 high_value,
4 tablespace_name
5 from user_ind_partitions;
INDEX_NAME PARTITION_NAME HIGH_VALUE TABLESPACE_NAME
------------------ ------------------------ ---------- ------------------------
IDX_T1_LOCAL PDEZENAS 100 TBS_DEZENAS
IDX_T1_LOCAL PCENTENAS 1000 TBS_CENTENAS
IDX_T1_LOCAL PMILHARES_1000 2000 TBS_MILHARES
IDX_T1_LOCAL PMILHARES_2000 3000 TBS_MILHARES
IDX_T1_LOCAL PMILHARES_3000 4000 TBS_MILHARES
IDX_T1_LOCAL PMILHARES_4000 5000 TBS_MILHARES
IDX_T1_LOCAL PMILHARES_N MAXVALUE TBS_MILHARES
Podemos também criar índices únicos locais, mas para isso a coluna chave de partição precisa obrigatoriamente fazer parte do índice, diferentemente dos índices globais não particionados. Se tentarmos criar um índice único local sem a coluna chave da partição, então o erro ORA-14039 será emitido:
SQL> create unique index idx_t1_local on t1 (cod) local;
create unique index idx_t1_local on t1 (cod) local
*ERRO na linha 1:ORA-14039: colunas particionadas devem formar um subconjunto de
colunas de chaves de um índice UNIQUE
Abaixo podemos ver que o índice será criado somente se a coluna chave da partição estiver presente:
SQL> create unique index idx_t1_local on t1 (id,cod) local;
Índice criado.
Já os índices particionados globais não precisam ser necessariamente particionados da mesma maneira que a tabela subjacente. A figura abaixo mostra claramente que o número de partições na tabela pode ou não, ser igual ao número de partições do índice.

Dependendo das operações DDL executadas nas partições da tabela (ADD, DROP, MOVE, TRUNCATE, SPLIT, MERGE, EXCHANGE ...) um índice global poderá ficar marcado como inutilizável (unusable). Portanto, utilizar a cláusula UPDATE GLOBAL INDEXES é uma boa prática:
SQL> ALTER TABLE ... DROP PARTITION P1 UPDATE GLOBAL INDEXES;
SQL> TRUNCATE TABLE ... UPDATE GLOBAL INDEXES;
SQL> ALTER TABLE ... DROP PARTITION P1 UPDATE GLOBAL INDEXES;
No caso de índices globais, para que o mesmo seja criado, ele deverá ser prefixado, ou seja, a coluna chave de partição precisará fazer parte do índice, caso contrário o erro ORA-14038: índice GLOBAL particionado deve ser prefixado será emitido. É importante frisar também que no caso de índices globais, criar uma partição com o limite (MAXVALUE) é obrigatória, caso contrário o erro ORA-14021 será emitido como demonstrado abaixo:
SQL> create index idx_t1_global on t1 (id)
2 tablespace users
3 global partition by range (id)
4 (partition idxp_1500 values less than(1500),
5 partition idxp_2900 values less than(2900),
6 partition idxp_4600 values less than(4600),
7 partition idxp_5000 values less than(5000));
partition idxp_5000 values less than(5000))
*ERRO na linha 6:ORA-14021: MAXVALUE deve ser especificado para todas as colunas
SQL> create index idx_t1_global on t1 (id)
2 tablespace users
3 global partition by range (id)
4 (partition idxp_1500 values less than(1500),
5 partition idxp_2900 values less than(2900),
6 partition idxp_4600 values less than(4600),
7 partition idxp_5000 values less than(5000),
8 partition idxp_n values less than(maxvalue));
Índice criado.
SQL> select index_name,
2 partition_name,
3 high_value,
4 tablespace_name
5 from user_ind_partitions;
INDEX_NAME PARTITION_NAME HIGH_VALUE TABLESPACE_NAME
------------------ ------------------------ ----------- -----------------------
IDX_T1_GLOBAL IDXP_1500 1500 USERS
IDX_T1_GLOBAL IDXP_2900 2900 USERS
IDX_T1_GLOBAL IDXP_4600 4600 USERS
IDX_T1_GLOBAL IDXP_5000 5000 USERS
IDX_T1_GLOBAL IDXP_N MAXVALUE USERS
A partir do Oracle 10g podemos também criar índices globais particionados por HASH como demonstrado abaixo:
SQL> create index idx_t1_global_hash on t1 (id)
2 tablespace users
3 global partition by hash (id)
4 (partition idxp1,
5 partition idxp2,
6 partition idxp3,
7 partition idxp4,
8 partition idxp5);
Índice criado.
SQL> select index_name,
2 partition_name,
3 high_value,
4 tablespace_name
5 from user_ind_partitions;
INDEX_NAME PARTITION_NAME HIGH_VALUE TABLESPACE_NAME
------------------ ------------------------ ---------- ------------------------
IDX_T1_GLOBAL_HASH IDXP1 USERS
IDX_T1_GLOBAL_HASH IDXP2 USERS
IDX_T1_GLOBAL_HASH IDXP3 USERS
IDX_T1_GLOBAL_HASH IDXP4 USERS
IDX_T1_GLOBAL_HASH IDXP5 USERS
Podemos notar que os índices globais não particionados são exatamente iguais aos índices regulares criados em uma tabela não particionada e, portanto, a sintaxe para a criação do índice é a mesma. A figura abaixo mostra o relacionamento entre um índice global não particionado e uma tabela particionada:

Por fim, vale a pena salientar que podemos criar também índices de bitmap em tabelas particionadas. A única restrição é que os mesmos só podem ser índice locais.